

Excelでのグラフ作成に追われる毎日から、解放されたいと思いませんか?
できる研究者は、もうその単純作業に時間を使っていません。
彼らが実践しているPythonを使った「グラフ作成自動化」のスキルは、もはや特別なものではなく、研究を加速させるための必須科目です。
この記事は、あなたがそのスキルを習得するための「最初の壁」として立ちはだかります。
しかし、ご安心ください。
この記事を読み終える頃には、あなたは壁を乗り越え、単純作業から解放され、より創造的な研究に集中するための、力強い第一歩を踏み出しているはずです。
【あわせて読みたい】
プログラミングがどう活きてくるのかを調査した記事は次で読めます。

はじめに:なぜ、できる研究者はExcelのグラフ作成に時間を使わないのか?

毎日、膨大な実験データを前に、グラフ作成という単調な作業に貴重な時間を溶かしてはいないでしょうか。
クリック、ドラッグ、コピー、ペースト… そのルーティンワークから解放され、もっと本質的な考察や、次の実験計画に時間を使いたい。
そう思ったことは一度や二度ではないはずです。
断言します。
できる研究者は、もうそのステージにはいません。
彼らは、単純作業をPythonという強力な相棒に任せ、自らはより創造的な領域へと歩を進めています。
この記事は、単なる便利ツールの紹介ではありません。
あなたがその「次のステージ」へ上がるための、最初の壁であり、乗り越えた先には大きな成長が待っている、挑戦的なチュートリアルです。
さあ、準備はよろしいでしょうか?ここから全てが始まります。
挑戦を始める前の「事前準備」
このチュートリアルに挑む前に、あなたのPCにPythonという工房を設置する必要があります。
また、コードを快適に記述するための専用エディタ(道具)も用意しておきましょう。
準備①:Python本体のインストール
PythonがまだPCにインストールされていない場合は、まずはこちらのインストールから始めましょう。
以下の記事が、MacとWindowsの両方について、非常に分かりやすく手順を解説してくれています。
参考記事: Pythonの学習環境を整えよう! – Progate
準備②:コードエディタのインストール
コードはメモ帳でも書けますが、専用の無料エディタ「Visual Studio Code」を使うことを強く推奨します。
コードの色分けや入力補助など、あなたの冒険を強力にサポートしてくれる最高の相棒です。
今回の挑戦:実験データを「再現可能なグラフ」に自動変換する
今回私たちが挑むのは、単なるグラフ作成ではありません。
研究者にとって最も重要な概念の一つである「再現性」を、プログラミングによって担保することです。
手作業でのグラフ作成は、クリックミスや設定のし忘れなど、ヒューマンエラーが入り込む余地が大きいです。
しかし、一度コードとして手順を記述してしまえば、誰が、いつ、何度実行しても、全く同じ品質のグラフを寸分違わず再現できます。
この挑戦を乗り越えるために、私たちは3つの強力な「力」を手にすることになります。
この挑戦で手にする「3つの力」
- 力①:
pandas(データ操作の力)
- 力②:
matplotlib(可視化の力)
- 力③:
openpyxl(Excel連携の力)
これらの力を手にするため、まずはターミナルを開き、以下の「合言葉」を唱えて、必要な武器(ライブラリ)をインストールしておきましょう。
Bash
pip3 install pandas matplotlib japanize-matplotlib openpyxl
さあ、武器は揃いました。いよいよ冒険の始まりです。
今回の挑戦で使う「架空の実験データ」を用意しよう
これから私たちは、Pythonを使ってグラフ作成を自動化していきますが、その前に、分析対象となる「実験データ」が必要です。
この記事では、多くの研究室でよくある「薬剤A, B, Cを投与した際の、細胞数の経時変化」を想定した、架空のExcelデータを使用します。
まずは、このデータをご自身の手で作成することから、今回の挑戦を始めましょう。
【原則】experiment_data.xlsx を手作りする
そして、script.pyファイルと同じフォルダ(※参考記事では「python_lesson」という名前)の中に、experiment_data.xlsx という名前で保存しましょう。
ヘッダーの文字列(1行目)は、一文字一句同じになるよう、細心の注意を払ってください。
ここが、最初の関門です。
| 時間 (Hour) | Sample_A | Sample_B | Sample_C |
| 0 | 100 | 110 | 95 |
| 1 | 120 | 140 | 110 |
| 2 | 150 | 180 | 130 |
| 3 | 180 | 230 | 160 |
| 4 | 200 | 260 | 180 |
【例外】Pythonだけでデータを完結させる方法
もし、Excelの作成でつまずいてしまった、あるいは、まずはPythonコードの動作だけを純粋に確認したい、という場合のために、Excelファイルなしでデータを完結させる方法も紹介しておきます。
その場合は、後述するscript.pyのdf = pd.read_excel(excel_file)という行を削除し、代わりに以下のコードブロックをimport文の直下に追加すれば良いです。
Python
# --- Excelを使わない場合のデータ作成コード ---
data = {
'時間 (Hour)': [0, 1, 2, 3, 4],
'Sample_A': [100, 120, 150, 180, 200],
'Sample_B': [110, 140, 180, 230, 260],
'Sample_C': [95, 110, 130, 160, 180]
}
df = pd.DataFrame(data)
# --- ここまで ---
準備はできましたでしょうか? さあ、お題は決まりました。
いよいよコーディングを開始しましょう。
【完成コード】まずは、この山の頂上からの景色を見てみよう

これから私たちが挑む「壁」の正体が、このコードです。
今はまだ、意味の分からない記号の羅列に見えるかもしれません。
しかし、心配は無用です。
この記事を読み終える頃には、あなたはこれを自在に操れるようになっています。
まずは、お使いのエディタ(Visual Studio Codeなど)でscript.pyファイルを開き、以下のコードを全てコピー&ペーストして保存してください。
Python
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
# --- ここからが設定項目 ---
# 読み込むExcelファイルの名前を指定
excel_file = 'experiment_data.xlsx'
# 保存するグラフ画像のファイル名を指定
output_image_file = 'result_graph.png'
# --- ここまでが設定項目 ---
# Excelファイルを読み込む
df = pd.read_excel(excel_file)
# グラフのキャンバスと4つの額縁(2x2)を用意する
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
# --- 個別のグラフを描画 ---
# 左上のグラフ (Sample_A)
axes[0, 0].plot(df['時間 (Hour)'], df['Sample_A'], marker='o', linestyle='-', color='b')
axes[0, 0].set_title('Sample A の経時変化')
axes[0, 0].set_xlabel('時間 (Hour)')
axes[0, 0].set_ylabel('測定値')
axes[0, 0].grid(True)
# 右上のグラフ (Sample_B)
axes[0, 1].plot(df['時間 (Hour)'], df['Sample_B'], marker='s', linestyle='--', color='r')
axes[0, 1].set_title('Sample B の経時変化')
axes[0, 1].set_xlabel('時間 (Hour)')
axes[0, 1].set_ylabel('測定値')
axes[0, 1].grid(True)
# 左下のグラフ (Sample_C)
axes[1, 0].plot(df['時間 (Hour)'], df['Sample_C'], marker='^', linestyle=':', color='g')
axes[1, 0].set_title('Sample C の経時変化')
axes[1, 0].set_xlabel('時間 (Hour)')
axes[1, 0].set_ylabel('測定値')
axes[1, 0].grid(True)
# --- 比較用のグラフを描画 ---
# 右下のグラフ (全サンプル比較)
axes[1, 1].plot(df['時間 (Hour)'], df['Sample_A'], marker='o', linestyle='-', color='b', label='Sample A')
axes[1, 1].plot(df['時間 (Hour)'], df['Sample_B'], marker='s', linestyle='--', color='r', label='Sample B')
axes[1, 1].plot(df['時間 (Hour)'], df['Sample_C'], marker='^', linestyle=':', color='g', label='Sample C')
axes[1, 1].set_title('全サンプルの比較')
axes[1, 1].set_xlabel('時間 (Hour)')
axes[1, 1].set_ylabel('測定値')
axes[1, 1].grid(True)
axes[1, 1].legend() # 凡例を表示
# グラフ全体のレイアウトを自動調整
plt.tight_layout()
# 作成したグラフを画像として保存する
plt.savefig(output_image_file)
print(f"グラフが {output_image_file} として保存されました。")
【暗号解読】コードの”意味”を理解し、自分の武器に変える

先ほどのコードは、一見すると複雑な暗号に見えたかもしれません。
しかし、その一つひとつには明確な「意味」と「役割」があります。
このセクションでは、コードをいくつかのパーツに分解し、その意味を解き明かしていきます。
単に理解するのではない。その意味を知り、あなたが自在に操れる「武器」に変えるのです。
Part1:出陣の準備(ライブラリとExcelの読み込み)
まずは、戦いに赴くための準備からです。必要な武器(ライブラリ)を呼び出し、分析対象となるデータ(Excelファイル)を読み込みます。
Python
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
# 読み込むExcelファイルの名前を指定
excel_file = 'experiment_data.xlsx'
# Excelファイルを読み込む
df = pd.read_excel(excel_file)
import pandas as pd: 「pandasというExcelを自在に操る魔法の道具箱を、pdというあだ名で使います」という宣言です。
import matplotlib.pyplot as plt: 「matplotlibという美しいグラフを描く絵筆セットを、pltというあだ名で使います」という宣言です。
import japanize_matplotlib: グラフのタイトルなどで日本語を使えるようにするためのおまじないです。
excel_file = '...':excel_fileという名の変数(箱)に、これから読み込むExcelファイルの名前を入れています。
df = pd.read_excel(...):pd(pandas)のread_excel()という機能で、指定したExcelファイルを読み込み、dfという名の巨大なデータ表に変換して格納しています。
Part2:作戦盤の用意(グラフの全体設計)
データを読み込んだら、次はそのデータを描き出すための「キャンバス」と「額縁」を用意します。
今回は、4枚の絵(グラフ)を田の字に並べたいので、特別な作戦盤を用意します。
Python
# グラフのキャンバスと4つの額縁(2x2)を用意する
fig, axes = plt.subplots(2, 2, figsize=(10, 8))
fig, axes = plt.subplots(...):plt(matplotlib)の機能で、「大きなキャンバス(fig)と、その中に配置する複数の額縁(axes)をください」という命令です。
(2, 2): 「額縁は、縦に2つ、横に2つ並べてください」という意味です。
figsize=(10, 8): キャンバス全体のサイズを「横10インチ、縦8インチ」で指定しています。
Part3:戦術の実行(個別のグラフ描画)
作戦盤(axes)に、私たちが読み込んだデータdfを描き込んでいきます。axesには[0, 0](左上)、[0, 1](右上)…といった住所が割り振られています。
左上のグラフ (axes[0, 0])
Python
# 左上のグラフ (Sample_A)
axes[0, 0].plot(df['時間 (Hour)'], df['Sample_A'], marker='o', linestyle='-', color='b')
axes[0, 0].set_title('Sample A の経時変化')
axes[0, 0].set_xlabel('時間 (Hour)')
axes[0, 0].set_ylabel('測定値')
axes[0, 0].grid(True)
右上のグラフ (axes[0, 1])
Python
# 右上のグラフ (Sample_B)
axes[0, 1].plot(df['時間 (Hour)'], df['Sample_B'], marker='s', linestyle='--', color='r')
axes[0, 1].set_title('Sample B の経時変化')
axes[0, 1].set_xlabel('時間 (Hour)')
axes[0, 1].set_ylabel('測定値')
axes[0, 1].grid(True)
左下のグラフ (axes[1, 0])
Python
# 左下のグラフ (Sample_C)
axes[1, 0].plot(df['時間 (Hour)'], df['Sample_C'], marker='^', linestyle=':', color='g')
axes[1, 0].set_title('Sample C の経時変化')
axes[1, 0].set_xlabel('時間 (Hour)')
axes[1, 0].set_ylabel('測定値')
axes[1, 0].grid(True)
右下のグラフ (axes[1, 1]):重ね合わせ
Python
# 右下のグラフ (全サンプル比較)
axes[1, 1].plot(df['時間 (Hour)'], df['Sample_A'], marker='o', linestyle='-', color='b', label='Sample A')
axes[1, 1].plot(df['時間 (Hour)'], df['Sample_B'], marker='s', linestyle='--', color='r', label='Sample B')
axes[1, 1].plot(df['時間 (Hour)'], df['Sample_C'], marker='^', linestyle=':', color='g', label='Sample C')
axes[1, 1].set_title('全サンプルの比較')
axes[1, 1].set_xlabel('時間 (Hour)')
axes[1, 1].set_ylabel('測定値')
axes[1, 1].grid(True)
axes[1, 1].legend() # 凡例を表示
Part4:勝利の記録(グラフの画像保存)
バラバラに描かれたグラフを美しく整え、一枚の画像として出力します。
これが最後の仕上げです。
Python
# グラフ全体のレイアウトを自動調整
plt.tight_layout()
# 作成したグラフを画像として保存する
plt.savefig(output_image_file)
print(f"グラフが {output_image_file} として保存されました。")
plt.tight_layout(): グラフのタイトルやラベルが重ならないよう、自動でレイアウトを調整してくれる便利な命令です。
plt.savefig(...): 作成した図(Figure)を、画像ファイルとしてPCに保存します。
print(...): プログラムが無事に最後まで動いたことを知らせる、勝利のファンファーレです。
【いざ実行】ターミナルで、魔法を唱える時が来た

script.pyにコードを書き込み、experiment_data.xlsxの準備もできた。
いよいよ、このプログラムに命を吹き込む時です。
Step1:ターミナルで、作業場所へ移動する
まずは、ターミナルを開き、cdコマンドを使って、script.pyとexperiment_data.xlsxを保存した「python」フォルダへ移動しましょう。
Bash
cd ~/Desktop/python/
Step2:実行の呪文を唱える
作業場所にたどり着いたら、いよいよ実行の時です。
以下の命令を打ち込み、Enterキーを押します。
Bash
python3 script.py
Step3:結果を確認する
実行すると、ターミナルには以下のようなメッセージが表示されるはずです。
グラフが result_graph.png として保存されました。
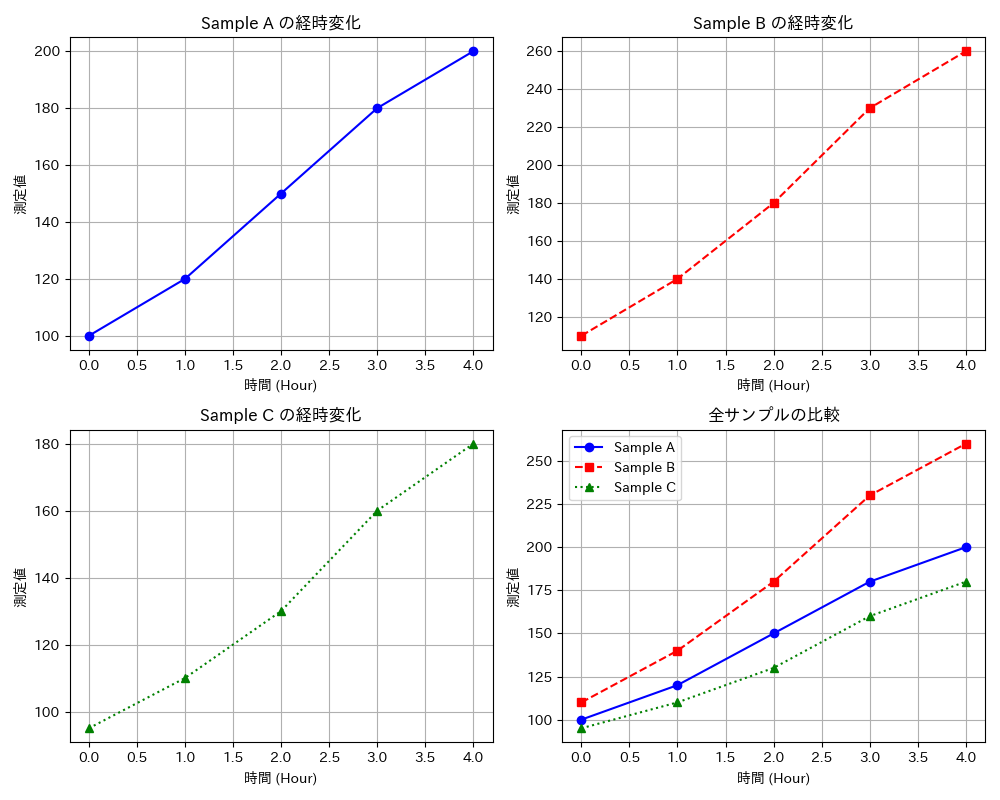
そして、あなたの「python」フォルダの中を見てください。 [result_graph.png]という名前の、新しい画像ファイルが生成されているはずです。
そのファイルを開いてみましょう。
そこに、4つのグラフが美しく描かれていれば、最初の壁は、突破されたのです。 おめでとうございます!
このコードを「あなた専用の分析ツール」に改造する

おめでとうございます。
あなたはこのコードという「最初の壁」を乗り越え、その意味を完全に理解しました。
しかし、本当の冒険はここからです。
このコードは、あくまで「ひな形」に過ぎません。
その真価は、あなたがこれを「あなた専用の分析ツール」に改造し、日々の研究で使いこなしてこそ発揮されます。
ここでは、そのための基本的な改造方法を伝授します。
改造ポイント①:ファイル名を変更する
自分のExcelファイル名に合わせて、コードの冒頭部分を書き換えます。
Python
# --- ここからが設定項目 ---
# 読み込むExcelファイルの名前を指定
excel_file = 'あなたのデータ.xlsx'
# 保存するグラフ画像のファイル名を指定
output_image_file = '2025-10-06_result.png'
# --- ここまでが設定項目 ---
改造ポイント②:グラフの見た目を変更する
グラフの色やマーカーの種類は、.plot()命令の中で自由に変更できます。
Python
# 例:Sample_Aのグラフを、緑色の破線(--)、四角いマーカー(s)に変更
axes[0, 0].plot(df['時間 (Hour)'], df['Sample_A'], marker='s', linestyle='--', color='g')
改造ポイント③:グラフのタイトルやラベルを変更する
もちろん、グラフのタイトルや軸ラベルも自由に変更できます。
Python
# 例:Sample_Aのグラフのタイトルを変更
axes[0, 0].set_title('薬剤X投与後の細胞増殖曲線 (Sample A)')
# 例:y軸のラベルを変更
axes[0, 0].set_ylabel('細胞数 (cells/mL)')
【転ばぬ先の杖】初心者が必ずハマる「4つのエラー」とその解決策

ここまでの道のりで、あなたもいくつかのエラー(壁)にぶつかったかもしれません。
素晴らしいことです。
エラーは、挑戦している者にしか現れません。
ここでは、あなたが今後何度も出会うであろう、代表的な4つのエラーとその乗り越え方を伝授します。
壁①:ModuleNotFoundError(武器が見つからない!)
- エラーの意味:
import pandasと命令したのに、「pandasという道具(モジュール)が見つかりません!」というエラー。
- 原因: Pythonをインストールした直後は、基本的な道具しか入っていません。
pandasなどは、後から自分で追加インストールする必要があります。
- 解決策: ターミナルで、
pip3 installという呪文を唱えます
Bash
pip3 install pandas matplotlib japanize-matplotlib openpyxl壁②:FileNotFoundError(設計図が見つからない!)
- エラーの意味: 「
experiment_data.xlsxというファイルが見つかりません!」というエラー。
- 原因: レシピ(
script.py)と、材料(experiment_data.xlsx)が、同じ厨房(フォルダ)に置かれていません。
- 解決策:
script.pyとexperiment_data.xlsxが、必ず同じフォルダの中に保存されているかを確認します。
壁③:KeyError(材料の名前が違う!)
- エラーの意味: 「
'時間 (Hour)'という列が見つかりません!」というエラー。
- 原因: Excelのヘッダー名と、コード内で指定した列名が、一文字でも違っています。
- 解決策: Python自身に「正解」を教えてもらいます。
df = pd.read_excel(...)の直後に以下の2行を追加して一度実行し、表示された「本当の列名」をコピーして、コードに貼り付け直します。
Python
# 調査用のコード(終わったら消す) print(df.columns) exit()壁④:結果が変わらない!(幽霊現象)
- エラーの意味: コードやExcelを修正したはずなのに、何度実行しても古いグラフが出力されてしまう現象。
- 原因: 99%「保存忘れ」です。コンピュータは、あなたが保存した時点のファイルしか見てくれません。
- 解決策: 「修正したら、必ず保存」を体に叩き込みます。
- Excelファイルを修正した場合: 必ず上書き保存(
command + S)してから、スクリプトを実行します。 - Pythonコード(
script.py)を修正した場合: こちらも必ず上書き保存(command + S)してから、実行します。
- Excelファイルを修正した場合: 必ず上書き保存(
まとめ:最初の壁を越えたあなたへ

ここまでたどり着いたあなたへ、心からの賛辞を贈ります。
あなたは、多くの初心者が挫折する「最初の壁」を、自らの力で見事に乗り越えました。
エラーとの戦いは、決して無駄な時間ではなかったはずです。
一つひとつの壁を乗り越えるたびに、あなたは問題解決の本質を学び、プログラマーとしての揺るぎない自信を手に入れました。
もう、あなたは以前のあなたではありません。
あなたは、単調な作業をPythonという強力な相棒に任せ、自らはより創造的で、本質的な問いに集中するための翼を手に入れたのです。
さあ、顔を上げて、胸を張ってください。
今日手に入れたその力で、あなたの研究を、そして未来を、どこまでも加速させていきましょう。
あなたの冒険は、まだ始まったばかりです。

